






从一条 INSERT 开始了解虚谷数据库存储设计

今日话题
从一条 INSERT 开始了解
虚谷数据库存储设计
NEWS
”
早在1975年Charles Bachman撰写的《Implementation Techniques for Data Structure Sets》与1980年 Abraham Silberschatz 等人合著的《Database System Concepts》这两部经典数据库教材中,便已对数据库的第一性原理进行了深刻阐述。Bachman 在书中将数据库定义为 “有组织、可共享的相关数据集合”,着重强调了其区别于文件系统的核心特征 —— 数据结构化与逻辑独立性。Abraham 等人在《Database System Concepts》中更是明确指出,DBMS 是一组程序,能够使用户创建和维护数据库,它作为通用软件系统,支持数据库的定义、构建、操作,并实现数据在不同用户和应用之间的共享。由此可见,数据库的第一性原理便是 “连接用户与数据的桥梁”。简单来讲,它是用户对数据进行 CRUD(创建、读取、更新、删除)操作的载体,并且设计了诸多机制来保障其可靠性、安全性和高效性。
虚谷数据库的设计同样紧紧围绕这一核心原理展开。无论是其产品整体架构,还是存储设计等细节,都是为了更好地实现 “连接用户与数据”,保障用户对数据的 CRUD 操作顺利进行。基于此,本文将围绕一条最简单直接的 “C”操作(在数据库中对应着创建表“CREATE”和增加数据“INSERT”,本文主要以INSERT为例),为您详细阐述虚谷数据库的存储体系设计,深入剖析它是如何通过精巧的架构和机制设计,践行数据库第一性原理的。
写在前面:虚谷数据库产品整体架构 - 简约
高效的线程模型
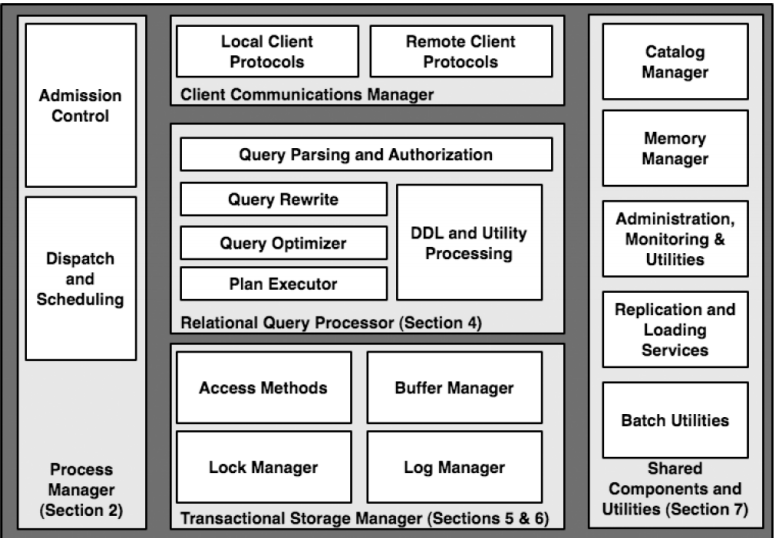
虚谷数据库采用标准的数据库设计思路,其组件涵盖语法分析与语义分析器、路径查询优化器、缓存系统、内存管理系统、数据字典系统、数据存取系统、日志管理系统、网络管理系统等。这些组件相互协作,共同搭建起用户与数据之间的桥梁,确保数据操作的高效与稳定。
横向对比虚谷数据库与Oracle、MySQL、PostgreSQL 的组件构成可以发现,尽管它们在具体实现上存在差异,但本质上都是由计算、存储、管理类组件构成。
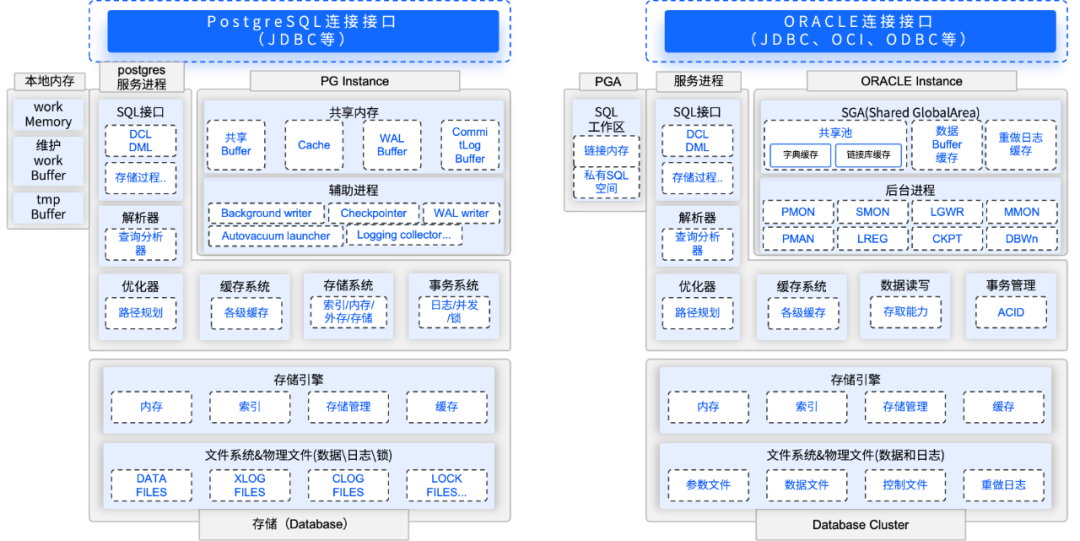

具体而言,虚谷数据库采用与MySQL 类似的单进程多线程设计思路,不过在文件存储系统、语法兼容以及用户管理方面,更倾向于 Oracle的管理方式(例如Database-User-Schema-Table-Partition 的逻辑管理体系)。
这种融合多种成熟设计的架构,既能保证性能,又能降低用户的使用门槛,进一步强化了与用户的连接。
当虚谷数据库引入分布式体系后,任务调度组件和网络管理组件会从本地化调度转变为RPC 远程调度,同时计算相关组件和存储相关组件也会变为分布式模型。
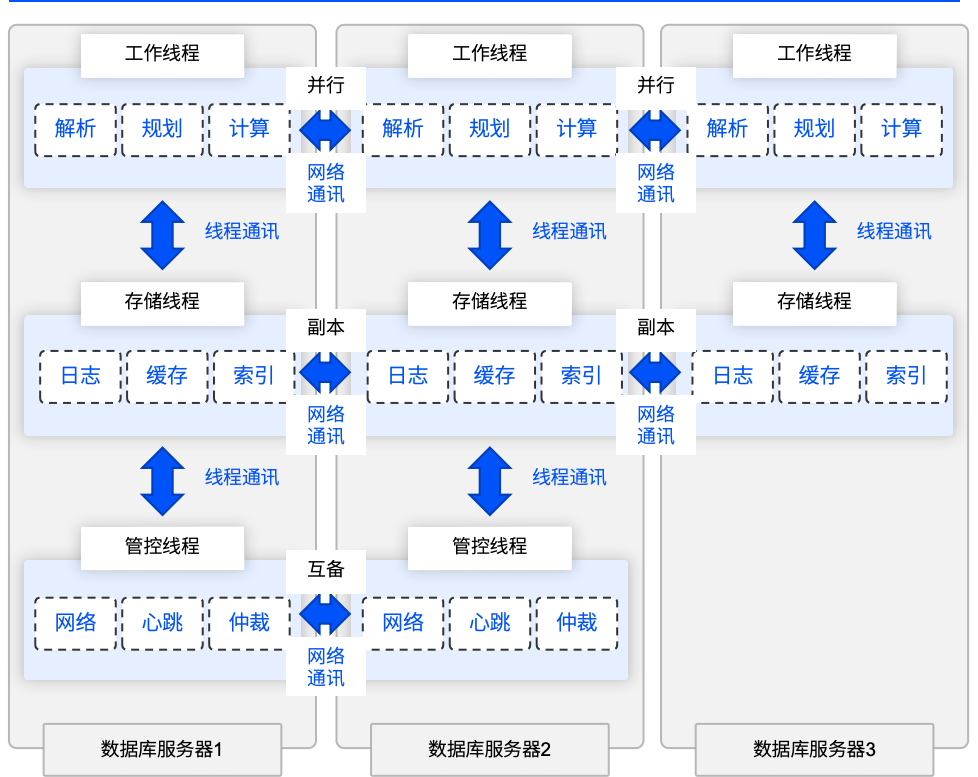
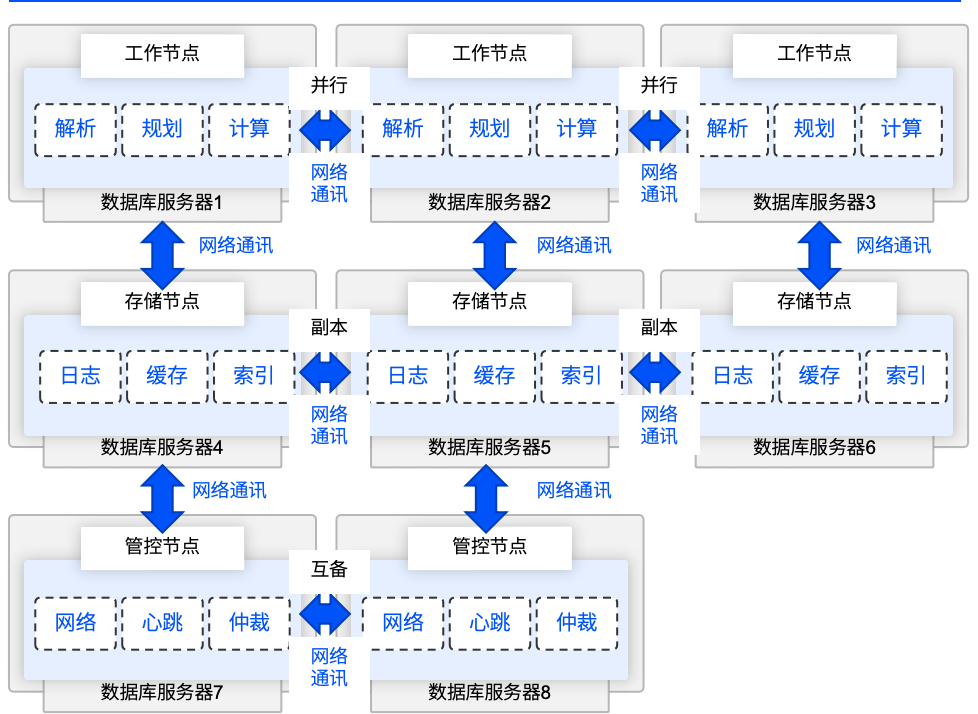
由于虚谷数据库采用多线程模型而非多进程模型,在云化或有较高弹性资源需求(即存算分离需求)时,可让部分线程与其资源池独占该进程,这些线程的集合被称为逻辑“节点”。从对硬件资源和处理任务的收敛角度,可分为工作(计算)、存储、管控三类节点:
主控管理角色:主要负责集群管理、全局控制、心跳检测、全局锁仲裁(检测死锁并解锁)等工作,不直接参与用户请求响应。它如同整个数据库系统的 “指挥官”,保障系统的稳定运行,为用户与数据的连接提供可靠的环境。
工作计算角色:用于接收和响应用户请求、进行路径规划和计算任务(SGA)。它是用户与数据交互的 “前线士兵”,直接处理用户的数据操作请求,将用户需求转化为对数据的具体操作。
存储管理角色:用于缓存数据(Cache)、操作数据、持久化数据等。它负责守护数据的存储与管理,确保数据能够安全、高效地存储和读取,实现用户与数据的稳定连接。
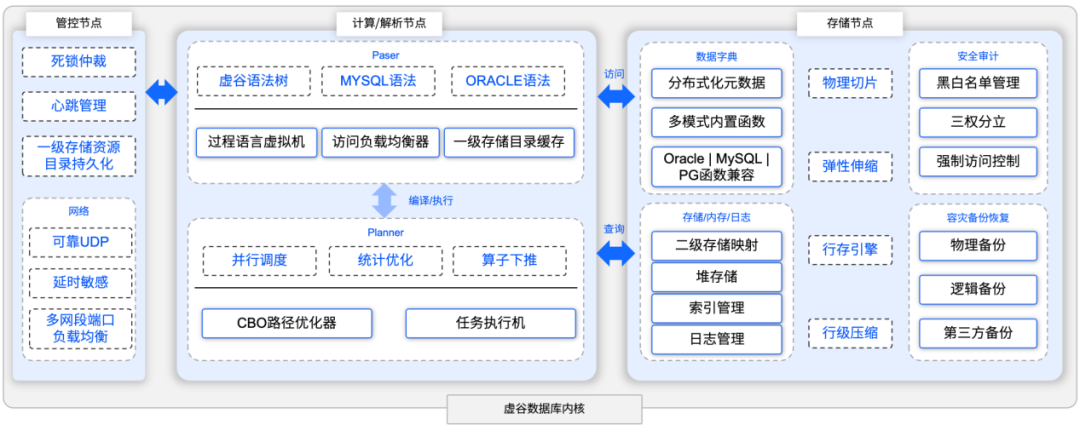
在单节点部署这种存算分离的模型下,三类节点间的通讯会从原来的线程交互转变为进程交互。而在分布式集群部署时,节点间的交互则变为网络交互。这种灵活的架构设计,适应不同的应用场景,始终围绕用户与数据的连接需求,提供高效、可靠的数据服务。如下图:
虚谷数据库的存储设计:与业务解耦的
物理切片存储模型
通过上一章节的介绍可知,虚谷数据库对外接收任务的是工作节点,负责SQL 解析、任务规划、路径优化等工作。要了解一条 INSERT 语句解析成存储任务后,在虚谷数据库内部如何进行存储空间的规划和写入,就需要先了解其存储设计。
虚谷数据库采用原生分布式架构体系,即无状态的SQL 引擎(工作节点)与通用的存储引擎(存储节点)相结合。其中,存储节点按照与逻辑表无关的方式,采用类似 Google-GFS 的物理切片规则,不过虚谷数据库的切片大小为 8MB(称为 Chunk),这样的设计便于数据的均衡、并发与迁移。虚谷的 Chunk由8K 大小的 Block(有的数据库叫Page)组成,Block中按顺序存储Row(Tuple),这种设计类似于Oracle的Segment-Extend-Block模型。
举例来说,假设有表1、表 2、表 3 三张不同字段数的表,各自有对应的分区规则。若表 1 的分区 1 有 2N 条记录,整体大小为 16M,那么分区 1 会占用 2 个 CHUNK。虚谷数据库的分区表是将一个表分成若干个逻辑分区,从物理上看这些分区是分离的,但从逻辑上看,这些分区组成的总表与未分区的表并无不同(这兼容了Oracle和MySQL 的分区管理方式)。当三张表同时往数据库中写入数据时,虚谷存储采用主版本物理轮转、副版本随机分布且与逻辑解耦的规则,所有表的主版本数据按写入顺序均衡存储在所有存储节点中。
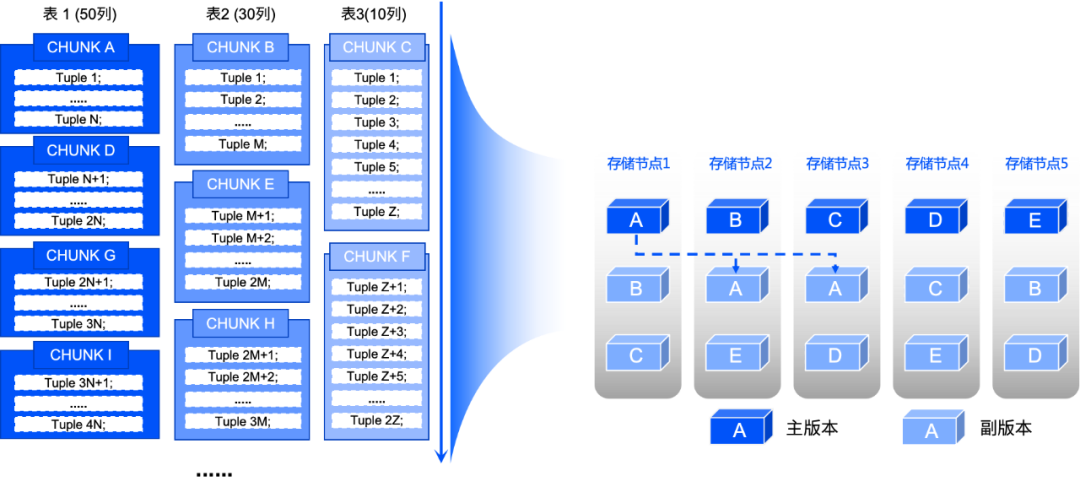
这种存储设计,将逻辑表与物理存储深度解耦,使用户无需关心数据实际的存储位置和方式,专注于业务操作。它通过标准化的数据分片- 映射 - 写入流程,实现了高效的数据存储和管理,是虚谷数据库践行 “连接用户与数据” 这一第一性原理的重要体现。它让用户在进行 INSERT 等数据操作时,感受到如同在操作简单数据库一般的便捷,同时又能享受分布式存储带来的强大性能和扩展性。
那么,当工作节点接收到SQL 请求后,如何知晓具体的数据落点呢?
这就需要引入虚谷数据库对存储切片管理的规则—— 两级存储映射机制。

虚谷数据库的两级存储映射主要是包括位于主控节点的GStore(全局映射信息)和存储节点的 LStore(本地映射信息):
GStore(全局映射信息):是分布式存储层的全局控制管理结构,存储于主控节点的全局存储系统表空间中。它是一个控制结构,不负责具体数据的存储,每个 GStore 都有唯一的 ID 编号,一个 GStore 只能与一个表实体对应,一个表实体由多个 GStore 组成,一个 GStore 对应最多 3 个节点上的 LStore,这 3 个 LStore 互为镜像。GStore结构里会存储LStore所在的节点号与局部ID号,以此完成与局部存储的映射关系。
LStore(本地映射信息):是分布式存储层的局部控制管理结构,存储于存储节点的局部存储系统表空间中。同样是控制结构,不存储具体数据,每个 LStore 有唯一的 ID 编号,一个 LStore 只能与一个 GStore 对应,一个 LStore 对应一个数据片。
注:GStore和LStore的数据结构采用的是一种类似链表的模型,其中0号Store结构作为自由链头,空闲Store通过Next顺序接入,这样在分配Store结构的时候,其时间复杂度为O(1)级,不会影响高并发时数据写入的效率。同时通过这样将存储映射持久化的方式,空间换时间,让数据存取更高效。
从工作任务来看:
全局存储管理工作在主控节点上,负责管理 GStore 控制结构,该结构存储于全局存储系统表空间中。主控节点的 GStore 信息会缓存至所有工作节点,以便在 SQL 处理后快速定位数据(若任务涉及存储体变更操作,则会与主控节点交互)。
局部存储管理工作在存储节点上,负责管理 LStore 控制结构,该结构存储于局部存储系统表空间中。
在虚谷数据库中,任何一条记录的存储位置都与GStore 和 LStore 相关,每一条记录的 Rowid 由 GStore、LStore 以及一些其他管理信息组成。两级映射机制以空间换时间,大大提升了数据定位效率,确保用户的数据操作能够快速、准确地执行,进一步强化了用户与数据之间的连接。
一条 INSERT 的一生
以表T1 的 INSERT 操作为例:
CREATE TABLE T1(ID INT , NAME VARCHAR(100) , AGE INT, COMPANY VARCHAR(100));
INSERT INTO T1 VALUES(1, '张三', 24, '虚谷');
INSERT INTO T1 VALUES(2, '李四', 32, 'IBM');
INSERT INTO T1 VALUES(3, '王五', 45, '微软');
....

具体步骤如下:
Step 1:工作节点的 Parser 对接收到的 SQL 进行解析,确定这是一个 “数据空间开辟” 的 Task。这是用户与数据连接的起点,工作节点将用户的 INSERT 语句转化为系统能够理解的任务。
Step 2-3:向管理节点申请分配存储空间,管理节点在 GStore 信息中进行注册,并将相关信息广播到所有工作节点,同时写入到三个存储版本对应的存储节点的 LStore 中。通过 GStore 和 LStore 的协作,为即将写入的数据确定存储位置,构建起数据存储的 “框架”。
Step 4:存储空间位置信息注册完成后,开始进行数据写入。虚谷数据库在一次数据写入时,需要写入页缓存、REDO/UNDO 日志、堆存储以及索引(若有)。虚谷的三个版本数据同步方式采用强同步机制,区别于 Paxos/Raft 多数派协议,需要等待所有副本均完成日志记录后才返回成功。这种方式虽然对网络时延较为敏感,但好处是可以容忍更多服务器同时宕机(可同时宕机 2 台节点,无需人工介入),在国产环境下的规模化部署中可靠性更强。它通过严格的数据同步机制,保障数据的一致性和可靠性,确保用户写入的数据能够安全存储,维护用户与数据之间可靠的连接。
Step 5:当数据完成日志持久化后,向工作节点返回成功 MSG。至此,一次 INSERT 操作完成,用户成功将数据写入数据库,实现了与数据的交互。
需要注意的是,上述流程仅列举了一个简单的INSERT 生命周期,未涉及索引、并发、分区等复杂场景,后续文章会陆续对这些内容进行阐述。
总结:写在最后
从一条简单的INSERT 语句入手,我们得以领略虚谷数据库存储体系的精巧设计:
以“连接用户与数据” 的第一性原理为核心,在分布式架构中构建了计算、存储、管控三权解耦的线程模型,通过 8MB 物理切片(Chunk)方式实现了逻辑表与物理存储的解耦。这种设计让用户无需关注底层复杂的存储细节,能够更专注于业务逻辑,降低使用门槛,优化用户与数据的连接体验。
两级映射机制(GStore 全局映射 + LStore 本地映射)以空间换时间,提升了数据定位效率,突破了传统关系型数据库的限制。区别于 Paxos/Raft 的强同步副本协议,在可靠性与性能之间找到了独特的平衡点,既能容忍双节点故障的极端情况,又能适应国产基础设施的网络环境,为规模化部署奠定了基础。它确保了数据操作的高效与稳定,保障用户能够快速、准确地访问和操作数据,强化用户与数据的连接。
虚谷存储设计的核心价值在于将复杂的分布式存储问题转化为标准化的“数据分片 - 映射 - 写入” 流程:
业务无感化:兼容 Oracle 与 MySQL 的分区管理逻辑,使用户无需改变使用习惯,即可享受分布式存储的弹性扩展能力。它消除了用户在使用过程中的障碍,让用户在熟悉的操作方式下,体验到强大的分布式存储功能,进一步拉近用户与数据的距离。
资源高效化:单进程多线程模型结合存算分离架构,使硬件资源利用率提升 30% 以上,在云化场景中实现计算与存储资源的独立扩容。这种高效的资源利用方式,不仅降低了成本,还能为用户提供更强大、更灵活的数据服务,满足用户不断变化的需求,巩固用户与数据的连接。
可靠内生性:从 Page 级缓存到 Chunk 级副本,从日志先行(Write-Ahead Log)到强同步协议,全链路保障数据一致性,让金融、政务等对可靠性敏感的场景无需额外适配。它为用户的数据提供了坚实的保障,让用户放心地进行数据操作,增强用户对数据的信任,深化用户与数据的连接。
在数据成为核心生产要素的时代,数据库的本质是“数据价值的连接器”。虚谷数据库的存储体系不仅是技术架构的创新,更是对 “连接” 的重新定义 —— 连接用户需求与底层硬件,连接传统开发习惯与分布式架构,连接可靠性要求与工程实现成本。这种化繁为简的设计哲学,让数据存储不再是业务发展的瓶颈,而是成为驱动创新的引擎。
未来,随着对索引优化、并发控制、智能调优等功能的深度解析,我们将看到虚谷如何在存储层之上构建更完整的数据库生态。从一条INSERT 语句开始,虚谷正在重新书写数据存储的高效与可靠范式,为企业级用户提供 “看得见的稳定,摸得着的高效”。

投稿:解决方案部
审核:技术部

本篇文章来源于微信公众号:虚谷数据库












